Audio Tokenizers
DASB includes a benchmark e benchmark a diverse set of discrete audio encoders from all three categories: semantic (Discrete HuBERT, Discrete WavLM, Discrete Wav2Vec2) , acoustic (EnCodec, DAC, WavTokenizer, SQCodec), and hybrid (SpeechTokenizer, and Mimi).
⚡ Key Features of the Discrete Audio Encoders
| Model | Abr. | SR | FR | #Vocab | Speech | Music | Sound |
|---|---|---|---|---|---|---|---|
| EnCodec [Defossez et al., 2022] | Enc-SMA-24 | 24kHz | 75 | 1024 | ✔ | ✔ | ✔ |
| DAC [Kumar et al., 2023] | DAC-SMA-24 | 24kHz | 75 | 1024 | ✔ | ✔ | ✔ |
| SpeechTokenizer [Zhang et al., 2023] | ST-S-16 | 16kHz | 50 | 1024 | ✔ | ||
| Mimi [Defossez et al., 2024] | Mimi-S-24 | 24kHz | 12.5 | 2048 | ✔ | ||
| Discrete WavLM [Mousavi et al., 2024] | DWavL-S-16 | 16kHz | 50 | 1000 | ✔ | ||
| Discrete HuBERT [Mousavi et al., 2024] | DHuBERT-S-16 | 16kHz | 50 | 1000 | ✔ | ||
| Discrete Wav2Vec2 [Mousavi et al., 2024] | DWav2Vec2-S-16 | 16kHz | 50 | 1000 | ✔ | ||
| SQ-Codec [SimpleSpeech, 2024] | SQ-SMA-16 | 16kHz | 50 | 20000 | ✔ | ||
| WavTokenizer [Ji et al., 2024] | WT-SMA-24-2 | 24kHz | 75 | 4096 | ✔ | ✔ | ✔ |
Runtime & Memor
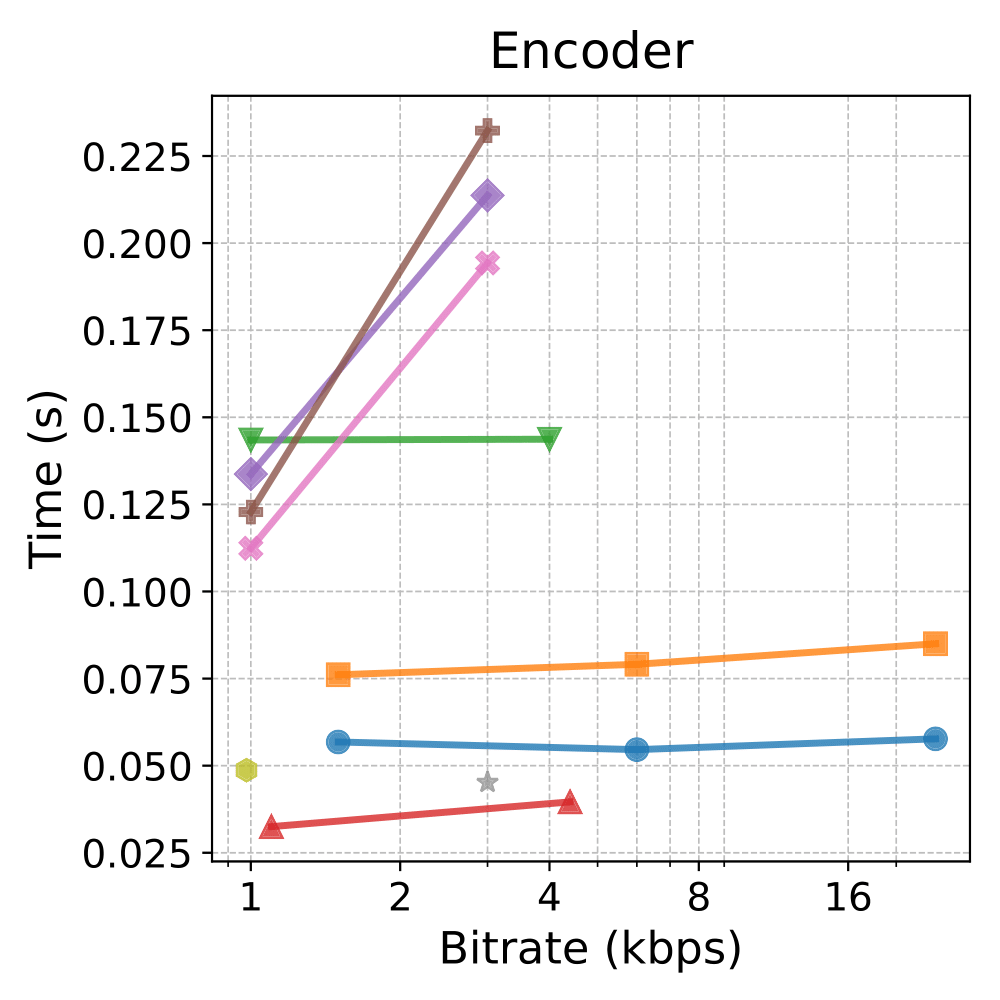
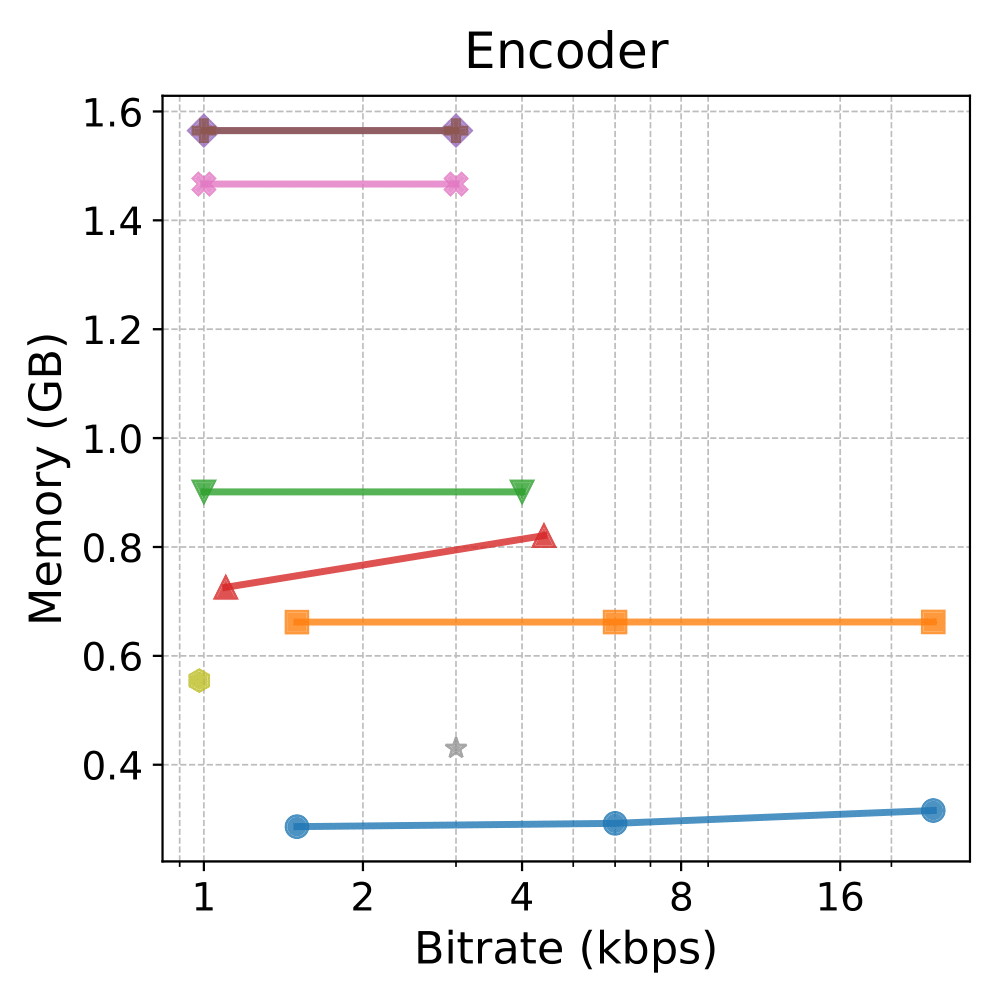
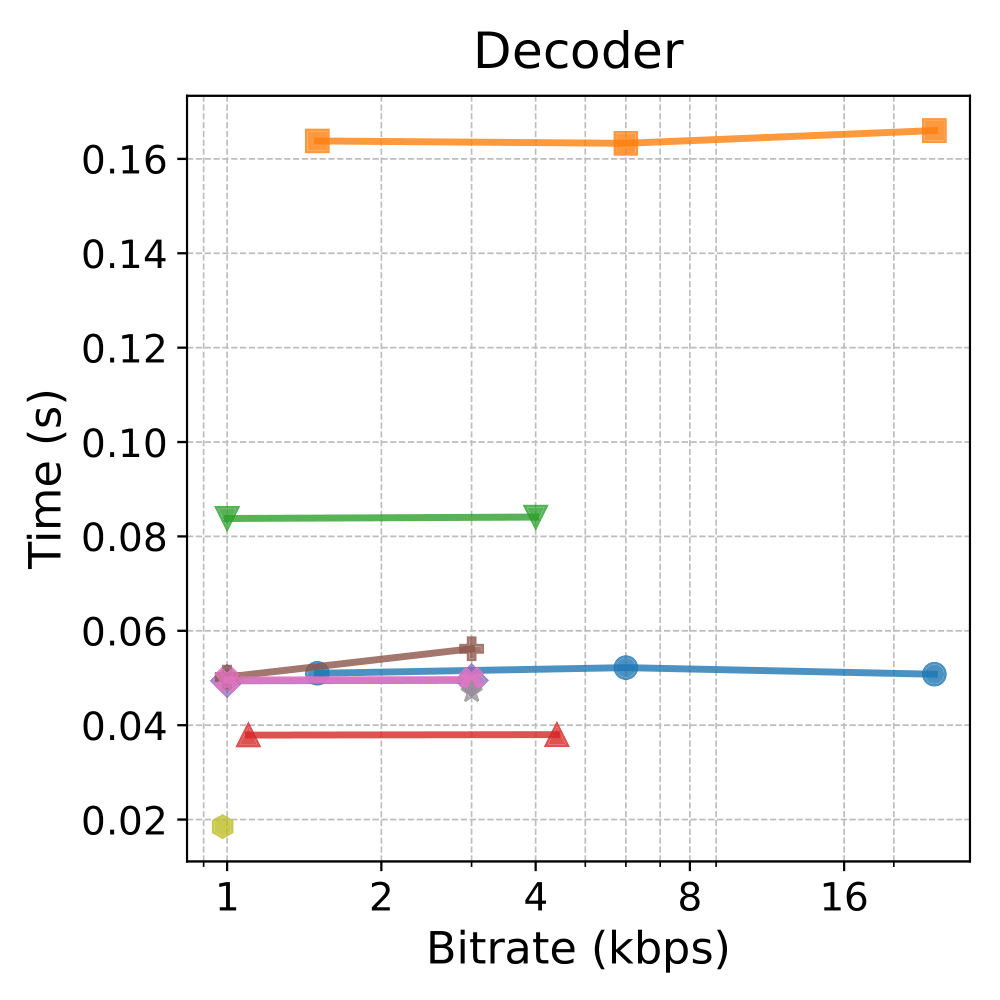
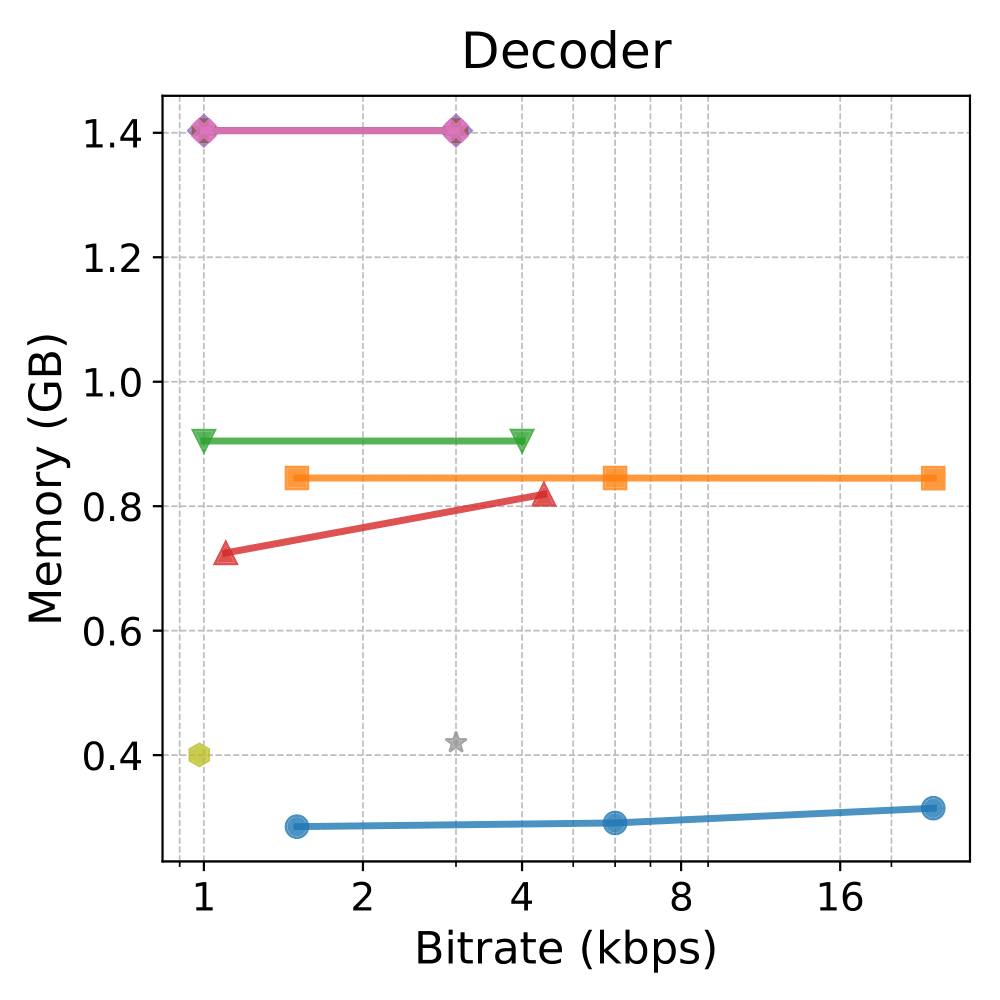
Notes: Shaded backgrounds/borders are for presentation only. Colors/markers match the legend above.